Cas d'étude : Analyse des téléchargements PyPI (GCP & Streamlit)
Découvrez en détails ma méthodologie pour la création d'un pipeline de données scalable.
🎯 Contexte & Objectifs
Analyse des données publiques issues de PyPI sur les téléchargements de packages Python, avec un pipeline automatisé sur GCP et Streamlit.
- Collecte automatique via Composer (Airflow)
- Traitement SQL avec BigQuery
- Dashboard interactif Streamlit
- Automatisation CI/CD via GitLab et Docker
📊 Dashboards & Visualisations
Quelques exemples concrets des dashboards interactifs réalisés :
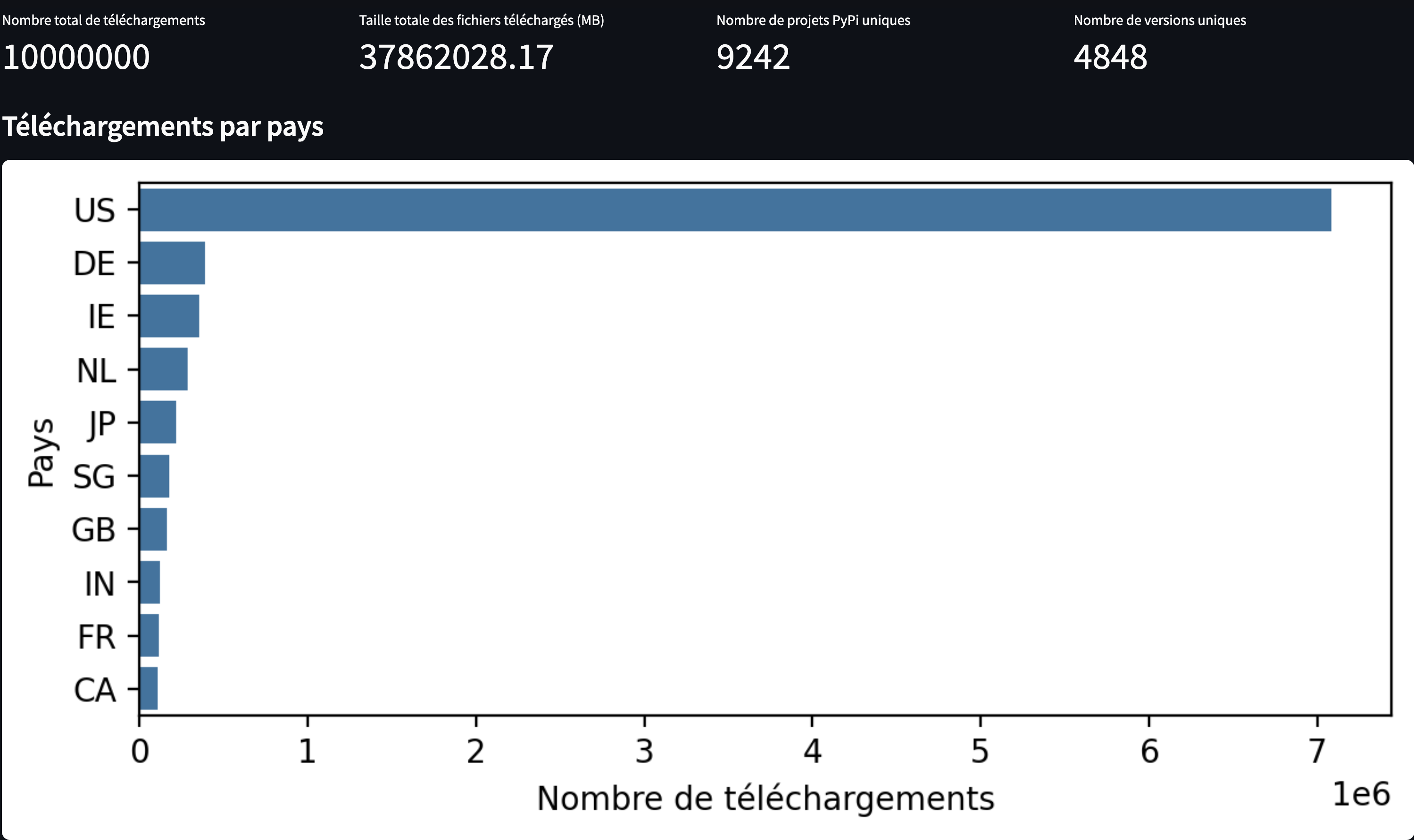
Téléchargements par Pays
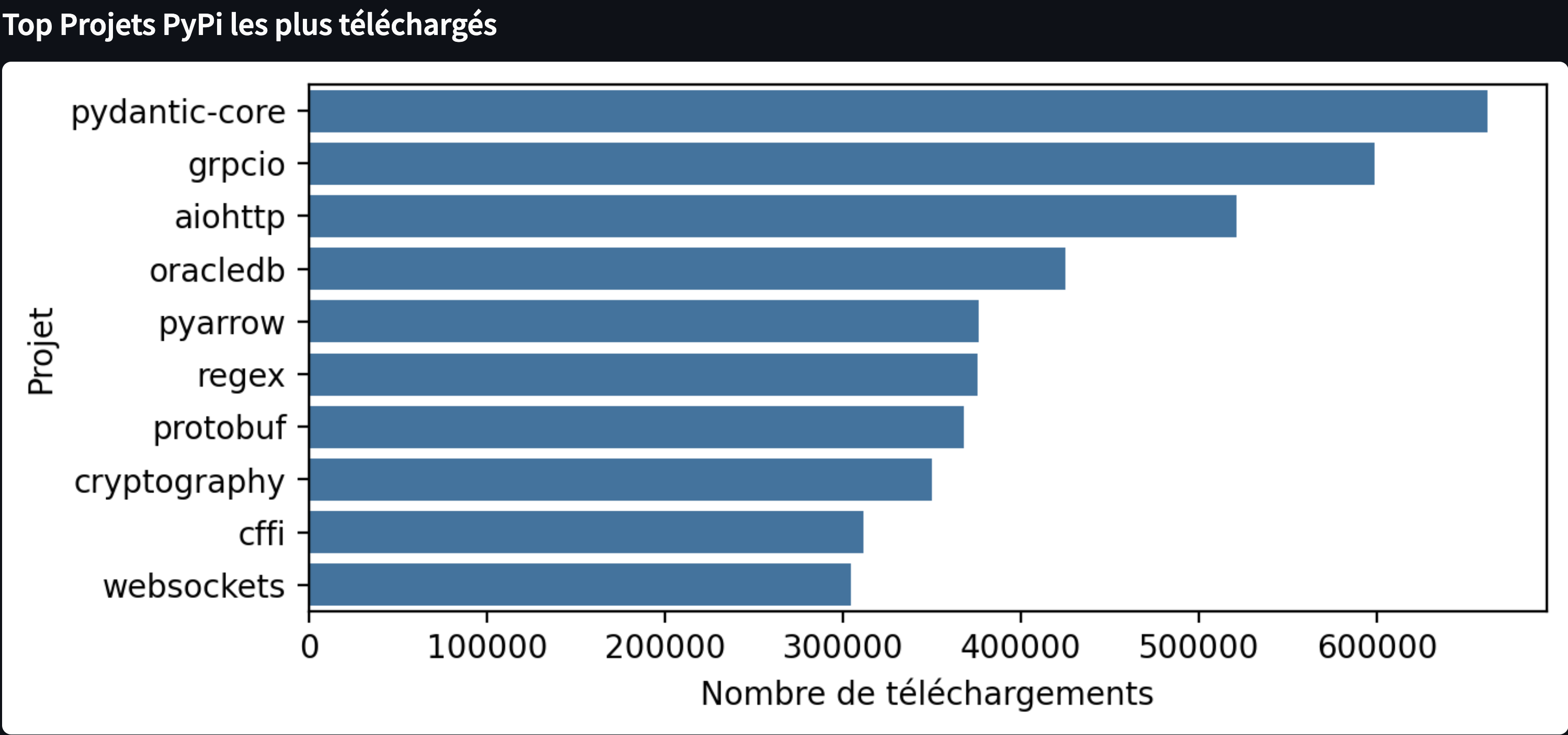
Top Projets PyPI téléchargés
Voir le Dashboard interactif
ℹ️
Lorsque vous ouvrez le dashboard, cliquez sur "Yes, get this app back up!" si un message s'affiche. Veillez patientez svp!
⚙️ Méthodologie & CI/CD
Workflow entièrement automatisé et géré via GitLab CI/CD et Docker, avec séparation nette des environnements dev et prod.
./deploy.sh prod
graph LR
A[Commit sur dev] -->|Trigger| B[Build Docker Image]
B -->|Push to Registry| C[Docker Hub / GCP Artifact Registry]
C -->|Merge Request Validé| D[Merge vers main]
D -->|Trigger Déploiement| E[Déploiement sur GCP Cloud Run]
E -->|🚀 App en ligne| F[Validation & Monitoring]
classDef success fill:#28a745,stroke:#fff,stroke-width:2px,color:#fff;
classDef process fill:#007bff,stroke:#fff,stroke-width:2px,color:#fff;
classDef warning fill:#ffc107,stroke:#fff,stroke-width:2px,color:#fff;
class A,B,C success;
class D process;
class E,F warning;